网上给娃找了些好看的电影和一些有趣的短视频,如何保存下来呢?从网上找各种工具?都不方便。于是想到何不编程搞定,搞个脚本。对程序员来说这都不是事儿。且我有华为云服务器,完全可以把地址记下,后台自动下载有空再看。这里总结分享下方法给有需要的小伙伴。
前言
【转载请注明出处】本文链接:https://blog.csdn.net/yyz_1987/article/details/133783787
很多网站视频不提供下载功能,遇到好的视频素材就难以下载。现在的好多在线视频都不是mp4的格式的了,查看链接是m3u8的链接。m3u8是一种播放列表文件格式,通常用于流媒体传输。它包含一系列的.ts(Transport Stream)文件的链接,这些文件包含了视频和音频的分段数据。m3u8文件本身并不包含实际的视频数据,而是指示播放器在何处获取分段视频文件。 为了防止盗版,以及流量和带宽的滥用,ts文件格式是一种视频分段的的技术,主要是需要一个索引文件列出该视频所有的分段信息,有时长和一些ts文件名的信息。
ts文件是一种常见的视频文件格式,用于存储音频、视频和其他多媒体数据。它是MPEG-2传输流的基础,也被广泛用于流媒体传输。ts文件通常是视频流的分段文件,每个文件包含一小段视频和音频数据。 在使用m3u8和ts文件时,m3u8文件作为播放列表提供给播放器,播放器会根据m3u8文件中的链接逐个下载ts文件,并按顺序播放这些分段视频文件,从而实现流媒体的播放。
ffmpeg介绍
ffmpeg是一个十分强大的音视频处理工具,提供转码、播放等基础功能,功能十分全面、强大。是一款非常好用处理音视频的软件工具包,在Win10中使用ffmpeg需要下载后再添加环境变量,下载网站:Download FFmpe
ffmpeg -i "https://v.rnaa.xyz/hls2/cl6z9guvr000212g0w9omylow/oRrc4hpOpuO/index.m3u8?auth=4skJHep0Po6jo0ieZpY2pgc_JktDisWQ3fIRk000Gds&exp=1697072400&v=6" -bsf:a aac_adtstoasc -c copy out.mp4 -http_persistent 0VLC播放器介绍
可以用VLC播放器来播放m3u8的网络流视频。
VLC是一款功能强大的开源播放器,VLC的全名为Video Lan Client,是一个开源的、跨平台的视频播放器。VLS支持多种常见音视频格式,支持多种流媒体传输协议,也可当作本地流媒体服务器使用。其官方下载地址为 https://www.videolan.org/
VLC: Official site - Free multimedia solutions for all OS! - VideoLAN
VLC功能很强大,不仅是一个视频播放器,也可以作为小型的视频服务器,一边播放一边转码,把视频流发送到网络上。
m3u8介绍
m3u8文件是指UTF8编码格式的M3U文件。m3u8文件是记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。m3u是包含媒体文件URL的一个事实上的播放列表标准,这种格式被用来作为HTTPLive媒体流索引文件的格式。
M3U8这种文件格式本质上不是音视频文件,而是一种音视频文件的列表文件,本身文件很小,采用的是用Latin1字符集编码,是纯文本文件。它并不能在脱机模式下读取网络资源音频。设计的初衷也是为了播放音频文件。而后来采用了UTF8编码就形成了M3U8格式文件,把一个大视频文件分割成若干小文件,通过M3U8记录保存音频,视频分块的列表地址。
我们只需在浏览器下载列表中选中需要合并转码的M3U8文件,简单操作即可将其转换成常见的MP4格式。
MP4格式,曾经是互联网上在线视频运用最广泛的一种格式,但是随着移动互联网用户日益增多,MP4文件格式的弊端也日益凸显,比如文件容量大需要加载很长时间才能播放,甚至有的播放器必须完全下载完毕才能播放。
反观M3U8格式,将视频文件切分成小片并建立索引文件,用户根据自己的网络带宽,可以选择适合自己码率的文件进行播放,从而保证了视频的流畅。虽然在网络播放过程中,M3U8格式比MP4格式更具优势。
其他网络短视频下载神器
浏览器的Video DownloadHelper插件:
https://download.csdn.net/download/u014519384/74704686
Chrome浏览器媒体网站的视频下载帮助插件,下载该插件压缩包,解压得到该插件.Crx文件,复制chrome://extensions/粘贴到Chrome浏览器地址栏,打开扩展程序界面,然后直接拖动解压得到的.Crx文件到浏览器打开的扩展程序窗口内,按提示,即可完成本插件安装。
如何找m3u8视频的文件地址?
1。搜索你的电影并打开正在播放的页面
2。打开“开发者工具” ,浏览器一般快捷键是:F12 。 如果没有反应,就找设置菜单的工具里找,什么?你浏览器没有? 那你换个正常点的浏览器吧。 我反正用谷歌、傲游、还有win10 自带的Microsoft Edge都是有的!
3。找到网络(Network)一栏,在搜索过渡栏里输入m3u8 。记得,这里要按 F5把页面重新打开刷新一次,因为刚开始打开时没开工具栏,所以看不到之前下载的信息。
如图:

注意上图中的 index.m3u8 , 不一定所有网站都是这名字,只要看后辍是m3u8就可以了,如果是有多个,就点最下面那一个。 在上面点右键 》 复制 》复制链接地址。 然后把复制的地址先存起来。 也可以放到本机上的VLC播放器里播放网络流试试。
其他短视频下载方式
如果是如头条或抖音的短视频,如何查看地址:
选择过滤类型media,然后复制下面的链接地址在浏览器里打开试试。
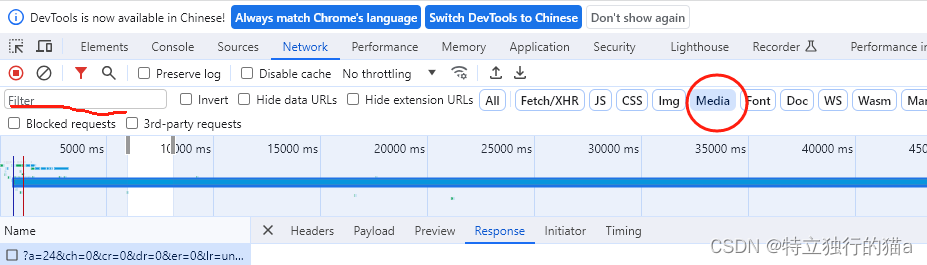
查看到类似如下内容,可以单独复制到浏览器中播放查看。
https://v26-web.toutiaovod.com/bf217da9d3d1faef4154643e118cff90/65276756/video/tos/cn/tos-cn-ve-4/o8BjgCDn6GbA2AZA1l2eArcRDl8n7RAHSCBCeg/?a=24&ch=0&cr=0&dr=0&er=0&lr=unwatermarked&net=5&cd=0%7C0%7C0%7C0&cv=1&br=440&bt=440&cs=0&ds=3&eid=21760&ft=7X_QHBWGUUmfzSdFD02D1YswHAX1tGDkdh49eFuBBR2D12nz&mime_type=video_mp4&qs=0&rc=Zzo6OTM7OTgzaTVkZDpkZkBpamRsdTM6ZmpwbjMzNDczM0BjMTY2LzEwNi4xYGFiL2EuYSNvb2otcjRnZWNgLS1kLS9zcw%3D%3D&btag=e00028000&dy_q=1697077398&l=20231012102318359BDF54C771C3838312或者使用you-get
You-Get是一个基于 Python 3 的下载工具。使用 You-Get 可以很轻松的下载到网络上的视频、图片及音乐。
pip3 install you-get
#或者
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple you-get
如:下载一段B站Python教学视频并保存在E:\Desktop
you-get -o E:/Desktop https://www.bilibili.com/video/av36938586带参数下载视频:
参数:-o 文件绝对路径
参数:-O 文件重命名
参数:--format=flv 需要下载的版本号
运行命令后,you-get将开始解析头条短视频的页面并提取视频的下载链接。然后,它将自动下载视频文件到您的当前工作目录中。 请注意,you-get可能无法支持所有头条短视频的下载,因为视频网站可能会进行更改或添加反爬虫机制。如果不能下载,则要寻找其他方式了。
python脚本下载m3u8视频
python环境依赖安装
pip install m3u8
pip install pycryptodomePython代码:
#这是一个下载m3u8 视频资源的脚本 无指定序号版,根据资源数组排序 非ffmpeg合并版
import os
import re
import sys
import m3u8
import glob
import time
import requests
import concurrent.futures
from Crypto.Cipher import AES
from concurrent.futures import as_completed
#请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'Zh-CN, zh;q=0.9, en-gb;q=0.8, en;q=0.7'
}
#判断是否为网站地址
def reurl(url):
pattern = re.compile(r'^((https|http|ftp|rtsp|mms)?:\/\/)[^\s]+')
m=pattern.search(url)
if m is None:
return False
else:
return True
#获取密钥(针对有些m3u8文件中的视频需要key去解密下载的视频)
def getKey(keystr,url):
keyinfo= str(keystr)
method_pos= keyinfo.find('METHOD')
comma_pos = keyinfo.find(",")
method = keyinfo[method_pos:comma_pos].split('=')[1]
uri_pos = keyinfo.find("URI")
quotation_mark_pos = keyinfo.rfind('"')
key_url = keyinfo[uri_pos:quotation_mark_pos].split('"')[1]
if reurl(key_url) == False:
key_url = url.rsplit("/", 1)[0] + "/" + key_url
res = requests.get(key_url,headers=headers)
key = res.content
print(method)
print(key.decode('utf-8','ignore'))
return method, key
#下载文件
#down_url:ts文件地址
#url:*.m3u8文件地址
#decrypt:是否加密
#down_path:下载地址
#key:密钥
def download(down_url,url,decrypt,down_path,key,nameid):
if reurl(down_url) == False:
if len(down_url.rsplit("/", 1))>1:
filename = down_url.rsplit("/", 1)[1]
else:
filename = down_url
down_url = url.rsplit("/", 1)[0] + "/" + down_url
else:
filename = down_url.rsplit("/", 1)[1]
down_ts_path = down_path+"/{0}".format(filename)
if os.path.exists(down_ts_path):
print('文件 '+filename+' 已经存在,跳过下载.')
else:
try:
res = requests.get(down_url, stream=True, verify=False,headers=headers)
print('正在下载资源:'+filename+'')
except Exception as e:
print('requests error:',e)
return
if decrypt:
cryptor = AES.new(key, AES.MODE_CBC, key)
with open(down_ts_path,"wb+") as file:
for chunk in res.iter_content(chunk_size=1024):
if chunk:
if decrypt:
file.write(cryptor.decrypt(chunk))
else:
file.write(chunk)
print('文件:['+filename+']已保存到['+down_path+']目录.')
#合并ts文件
#dest_file:合成文件名
#source_path:ts文件目录
#ts_list:文件列表
#delete:合成结束是否删除ts文件
def merge_to_mp4(dest_file, source_path,ts_list, delete=False):
files = glob.glob(source_path + '/*.ts')
if len(files)!=len(ts_list):
print("文件不完整,已取消合并!请重新执行一次脚本,完成未下载的文件。\n如果确认已下载完所有文件,请检查下载目录移除其它无关的ts文件。")
return
print('开始合并['+source_path+']目录的ts视频...')
with open(dest_file, 'wb') as fw:
for file in ts_list:
with open(source_path+"/"+file, 'rb') as fr:
fw.write(fr.read())
if delete:
os.remove(file)
print('合并完成! 文件名:'+dest_file+'')
def main():
url = "https://xxxx/hls/index.m3u8" #下载地址,通过 cmd 传入或输入
print('\n')
print('参数说明:脚本后面面添加 m3u8地址参数,如打开CMD(终端命令)模式输入:m3u8dl http://xxx.xxx.com/xxx.m3u8')
print('\n')
print(' 如果m3u8地址访问不到,提示错误,多重复几次就好。前提是确认在线能观看可下载到m3u8文件。')
print(' 下载中途不动了或者关机,可关闭取消下载,再次打开继续下载。')
print(' 有些文件一次下载不到,需要多次执行下载。')
print(' 等所有文件下载完后自动合成一个视频,注意看提示。')
print('\n')
if len(sys.argv)>1:
url=(sys.argv[1])
else:
print('亲,没有添加m3u8地址,请在下方输入:')
url=input()
#禁止安全谁提示信息
requests.packages.urllib3.disable_warnings()
print('开始分析m3u8文件资源...')
#使用m3u8库获取文件信息
try:
video = m3u8.load(url, timeout=20, headers=headers)
except Exception as e:
print('m3u8文件资源连接失败!请检查m3u8文件地址并重试.错误代码:',e)
return
#设置下载路径
down_path="tmp"
#设置是否加密标志
decrypt = False
#ts列表
ts_list=[]
#判断是否加密
key=''
if video.keys[0] is not None:
method,key =getKey(video.keys[0],url)
decrypt = True
#判断是否需要创建文件夹
if not os.path.exists(down_path):
os.mkdir(down_path)
#把ts文件名添加到列表中
for filename in video.segments:
if len(filename.uri.rsplit("/", 1))>1:
ts_list.append(filename.uri.rsplit("/", 1)[1])
else:
ts_list.append(filename.uri)
#开启线程池
with concurrent.futures.ThreadPoolExecutor() as executor:
obj_list = []
begin = time.time()#记录线程开始时间
for i in range(len(video.segments)):
obj = executor.submit(download,video.segments[i].uri,url,decrypt,down_path,key,i)
obj_list.append(obj)
#查看线程池是否结束
for future in as_completed(obj_list):
data = future.result()
# print('completed result:',data)
merge_to_mp4('finalvideo.mp4', down_path,ts_list)#合并ts文件
times = time.time() - begin #记录线程完成时间
print('总消耗时间:'+str(times)+'')
if __name__ == "__main__":
main()其他资源
【音视频基础】VLC播放器 - 知乎
使用Python脚本调用ffmpeg下载ts分段视频文件_python下载ts文件-CSDN博客
https://www.cnblogs.com/bjguanmu/articles/13044378.html
使用Python脚本调用ffmpeg下载ts分段视频文件 - 知乎
VideoDownloadHelper插件安装与使用 - 知乎
曲线救国-解决FFmpeg下载m3u8视频中途卡住的问题_ffmpeg下载m3u8太慢_myth long的博客-CSDN博客
VideoDownloadhelper无限制_网络视频解析下载_MP4_支持多平台 - 知乎
使用EasyDarwin + ffmpeg 搭建流媒体服务器,实现多台智能电视同步播放宣传视频_ffmpeg推流多个视频_三棵树机务段的博客-CSDN博客
常见流媒体服务器方案对比分析 - 知乎